
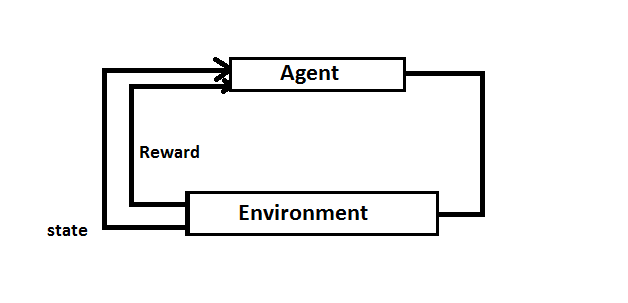
If we have no pre-defined data and unknown output then obviously we will apply a reinforcement learning algorithm and model. In this case, we need an agent and an environment for the performance. The agent learns to behave in the environment by performing actions and seeing results.
Some key terms used in this learning
Agent: The RL algorithm that learns trials and error
Environment: The world through which the agent moves
Action (A): All the positive steps that the agent could take
State (S): The environment’s returned current condition
Reward (R): For appraising the last action of an instant return from the environment
Policy (π): The approach that the agent uses to differentiate the next action based on the current state
Value (V): Expected long-term return with discount, as opposed to the short-term reward R
Action-value (Q): It is similar to the value except it takes the current action (A) as an extra parameter.
Before we get started we should have to know about concepts
Reward maximization: For getting maximum reward an agent must be trained in such a way that he takes the best action
Exploitation: It is about using the already known exploited information
Exploration: It is about exploring and capturing more information
Now the most important thin
Markov’s decision process: It is a mathematical process/approach for mapping a solution.
Now we will show only one algorithm which is
Q-learning
In this algorithm first, define a problem then define the state then we define the actions and lastly, we define the reward. In the reward, we make a list of states and a set of actions.
Now we make the reward matrix
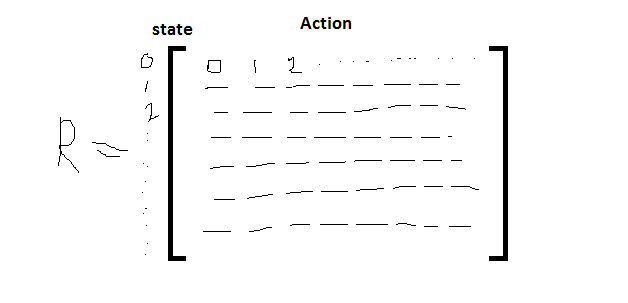
Step by step process is
- set gamma parameter and environment matrix
2. initialize matrix to zero
3. select a random state
4. initial state=current state
5. select one among all possible actions for the current state
6. using that go top next state
7. get max Q value for the next state based on all positive actions
8 then compute: Q(state, action)= R(state, action) + Gamma*max[Q(next state, allocations)] and repeat that until current state=goal state
The reinforcement learning algorithm and model approach follow the trial and error method. Another algorithm is SARSA. This algorithm works always in an environment.

No responses yet