
If we have the labelled data and known output then obviously we will apply a supervised learning algorithm and model. But according to the data, we apply different algorithms to predict the most accurate result. Those algorithms are
Linear Regression
In this method, we predict the dependent variable based on the values of the independent variable. If the data has no categorical variable then we can apply the Linear Regression model.
Equation is Y=b0+bx+e
e is an error, x is independent and Y is the dependent variable, b is slope and b0 is Y-intercept

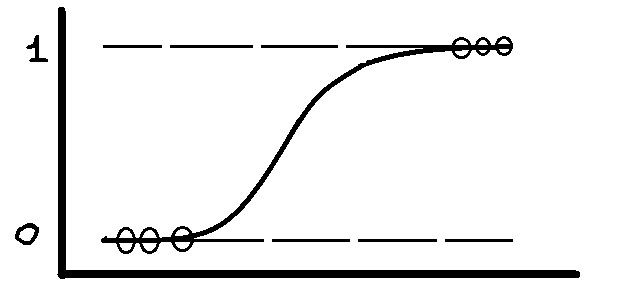
Logistic Regression
In this method, we also predict the dependent variable from independent variables but the dependent variable is categorical. For linear, it is not categorical.
Equation is
P(X)=e(b0+b1x) / (e(b0+bx) +1)
after soluting this equation we get
ln[p/(1-p)]=(b0+b1x)
Decision tree
It is an inverted tree-like algorithm. where each node is a predictor variable or feature. The link between the nodes represents a decision and each leaf nodes an outcome. At the top is the Root node, then branches for getting internal nodes for predictor and finally at the end we get the final classes.
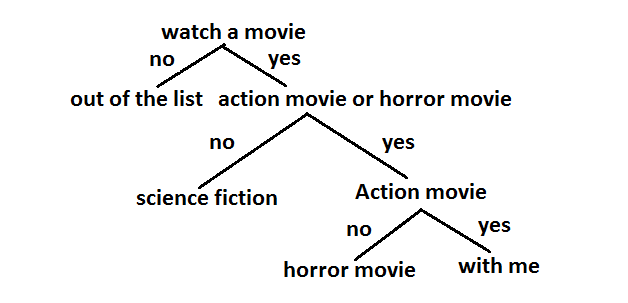
First, select the best attribute, then assign A as a decision variable for the root node, then each A builds a descendent of the node, then assign classification labels for leaf nodes, then if or at the point, the data is correctly classified, stop.
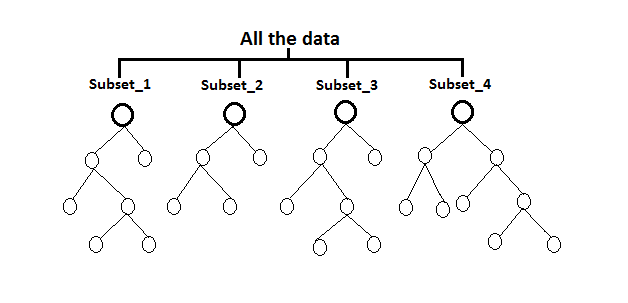
Random Forrest
In the decision tree, we face some problems in accuracy, overfitting, bagging etc. At that time we apply this algorithm. In this process, we build multiple decision trees and attach them together to get a more accurate prediction.
In this case, we make subsets of all the data, bootstrapping the set. Then for each, we create a decision tree. Then evaluate the model.
Naive Bayes
It is completely based on the Bayes theorem which is used to solve classification problems by using a probabilistic approach. In a model, there are lots of predictor variables and we have to predict those predictor variables. Simply they are independent of each other.
Equation is
P(A|B)={P(B|A)P(A)}/P(B)
P(A|B)= Probability of A occurring, given B
P(B|A)= Probability of B occurring, given A
P(B)= Probability of B
P(A)=Probability of A
KNN (K-nearest Neighbour)
In this algorithm we classify a new data point into a target class, depending on the features of its neighbour data points. Simply, we have some data points it has some features, and we will classify another data point by using Euclidean distance. In this case, we differentiate into different classes.
Non-parametric, Simple, Lazy algorithm, based on feature similarity etc.
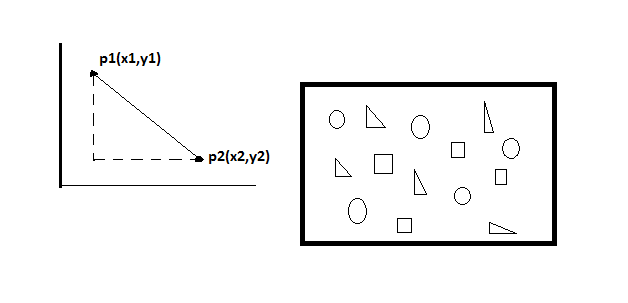
The mathematical form of the equation is (x2-x1)2+(y2-y1)2
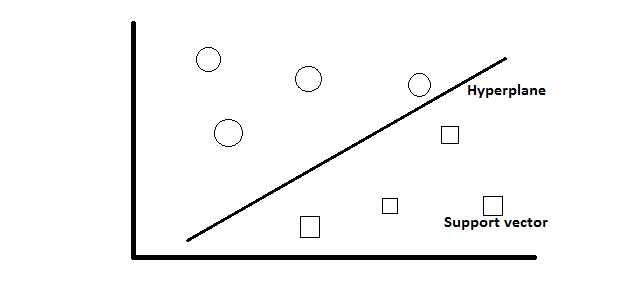
Support Vector Machine (SVM)
It has two different visualizations. One is in 2-D and another one is in 3-D. In this case, we separate the data using a hyperplane. We make two classes and then draw a line between those classes which is a hyperplane and the points are support vectors.
We use the kernel function to take the input data to transform them into the required form. It is both a classification and regression algorithm.
Whenever we apply any library or make a model then we have to do some operation in the data. Obviously, modification is needed to prepare the data. Then we have to see which supervised learning algorithm and model are fitted or give more accuracy, then go for it.

No responses yet