
If we have the unlabelled data and unknown output then obviously we will apply an unsupervised learning algorithm and model. But according to the data, we apply different algorithms to predict the most accurate result. Those algorithms are
Before we get started we should have to know about clustering. It is the process of dividing the datasets into groups, consisting of similar data points. That means, we have to group the objects based on the information in the data, description of the objects and relations.
K-means clustering
In this process, we classified objects into a predefined number of groups so that they are dissimilar as possible from one another group. But, we have to remember that they have similarities as much as in each group.
Steps are
Decide the number of clusters—>provide centroids—>Euclidian distance of the points from each centroid and assign—> then calculate next one if we have a new cluster—>again, the distance of the points from each centroid and assign—>again, calculate next one if we have a new cluster—>we have to calculate until the centroid is very close to the previous one
Elbow method: Deciding the number of clusters is done by this method. First, we compute SSE, for some values of k. The SSE is defined as the sum of the between each member of the cluster’s squared distance.
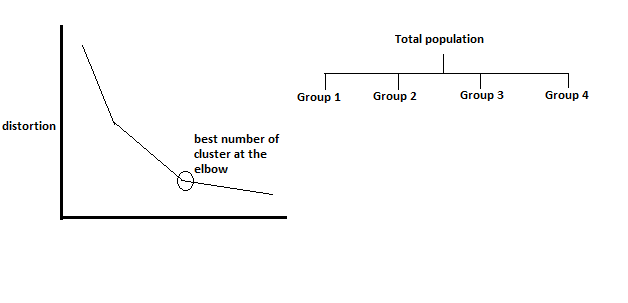
C-means clustering
It is an extension of the previous one. It is a form of clustering in which each data point can belong to many clusters. So that it can involve multiple functions.

Apriori Algorithm
It uses frequent item sets to generate association rules. A subset of a frequent item set must be a frequent itemset. Frequent item set means whose support value is greater than the threshold value

Each and every step we have to calculate the support value. After performing in the dataset then calculate the support value. If any of the subsets of these items sets are not there then we remove that itemset. We have to do again iteration until we collect our confidence value and apply it to different item rules.
Unsupervised learning algorithm and model used in the banking sector, retail stores etc. Manly where unstructured data are huge. Audio clips, video clips etc. type of. These are not labelled.

No responses yet